L’intelligenza artificiale ancora non è stata completamente progettata, i ricercatori stanno costantemente insegnando al computer come vedere, leggere, e capire il nostro mondo. Il mese scorso, gli ingegneri di Google hanno mostrato il loro “Deep Dream“, un programma in grado di “imparare” a identificare i vari tipi d’immagini con sempre maggiore precisione e accuratezza. Il programma attraverso milioni di tentativi ed errori, ha sviluppato la capacità di determinare quali caratteristiche di ogni singola immagine ha più probabilità di rappresentare un oggetto particolare.
Il software di Google segue la ricerca degli scienziati della Stanford University, hanno sviluppato un programma simile denominato NeuralTalk, in grado di analizzare le immagini descrivendole con frasi molto accurate.
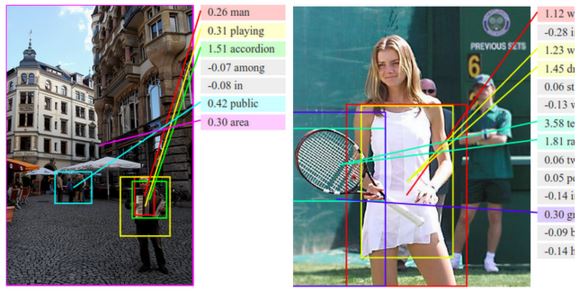
Il programma pubblicato la prima volta lo scorso anno, è lo studio e lavoro di Fei-Fei Li direttrice del laboratorio d’intelligenza artificiale di Stanford, e Andrej Karpathy, uno studente laureato. Il loro software è in grado di guardare le immagini di scene complesse e identificare esattamente cosa sta succedendo. Un ritratto di un uomo in camicia nera mentre suona la chitarra, è descritto come “l’uomo in camicia nera suona la chitarra”, mentre altre immagini come quella di un cane bianco che salta, un uomo in una muta blu che fa surf sull’onda, e una bambina piccola che mangia la torta, sono correttamente descritte con una sola frase.
Il software di NeuralTalk come quello di “Deep Dream” di Google utilizza una rete neurale per capire cosa sta succedendo in ogni immagine, confronta elementi d’immagine che ha già visto, descrivendole come farebbero gli esseri umani. Le reti neurali sono state progettate per essere come il cervello umano, funzionano un po’ come i bambini, una volta che hanno imparato i principi fondamentali del nostro mondo per esempio, “questa è una finestra”, “questo è un tavolo”, “quello è un gatto che cerca di mangiare un cheeseburger”, poi si può applicare questa comprensione per altre immagini e video.
NeuralTalk come dimostra questo demo dal set di 1000 immagini:
– il numero giallo in alto a sinistra di ogni immagine è riferito al punteggio;
– cliccando su ogni immagine rivela i suoi dettagli;
– il bordo rosso indica il recupero inesatto;
– il bordo verde indica il recupero corretto,
non è ancora perfetto ma già s’intravvede la sua potenzialità considerando che l’incredibile quantità d’informazioni visive su Internet fino a poco tempo fa dovevano essere etichettate manualmente per essere ricercabili e che Google prima di lanciare Google Maps, si è basata su un team impegnato a controllare ogni singola voce, ogni numero per assicurarsi che corrispondevano a un indirizzo reale.
Google al termine di un lavoro così faticoso, ha progettato Google Brain una rete neurale composta di migliaia di microprocessori, in grado di formare le proprie conoscenze esplorando la Rete, in pratica dove in precedenza serviva un team impegnato a lavorare diverse settimane per completare l’operazione, Google Brain in meno di un’ora potrebbe trascrivere tutti i dati di Street View della Francia.
Fei-Fei Li l’anno scorso al New York Times ha detto: «Considero i pixel delle immagini e dei video come la materia oscura di Internet. Solo adesso iniziamo a illuminarla».
A guidare la carica per quell’illuminazione sono giganti web come Facebook e Google, desiderosi di passare al setaccio e categorizzare milioni d’immagini e risultati di ricerca di cui hanno bisogno.